Simon Josefsson: Towards reproducible minimal source code tarballs? On *-src.tar.gz
While the work to analyze the xz backdoor is in progress, several ideas have been suggested to improve the software supply chain ecosystem. Some of those ideas are good, some of the ideas are at best irrelevant and harmless, and some suggestions are plain bad. I d like to attempt to formalize two ideas, which have been discussed before, but the context in which they can be appreciated have not been as clear as it is today.
- Reproducible tarballs. The idea is that published source tarballs should be possible to reproduce independently somehow, and that this should be continuously tested and verified preferrably as part of the upstream project continuous integration system (e.g., GitHub action or GitLab pipeline). While nominally this looks easy to achieve, there are some complex matters in this, for example: what timestamps to use for files in the tarball? I ve brought up this aspect before.
- Minimal source tarballs without generated vendor files. Most GNU Autoconf/Automake-based tarballs pre-generated files which are important for bootstrapping on exotic systems that does not have the required dependencies. For the bootstrapping story to succeed, this approach is important to support. However it has become clear that this practice raise significant costs and risks. Most modern GNU/Linux distributions have all the required dependencies and actually prefers to re-build everything from source code. These pre-generated extra files introduce uncertainty to that process.
*-src.tar.gz with at least the following properties:
- The tarball should allow users to build the project, which is the entire purpose of all this. This means that at least all source code for the project has to be included.
- The tarballs should be signed, for example with PGP or minisign.
- The tarball should be possible to reproduce bit-by-bit by a third party using upstream s version controlled sources and a pointer to which revision was used (e.g., git tag or git commit).
- The tarball should not require an Internet connection to download things.
- Corollary: every external dependency either has to be explicitly documented as such (e.g., gcc and GnuTLS), or included in the tarball.
- Observation: This means including all
*.pogettext translations which are normally downloaded when building from version controlled sources.
- The tarball should contain everything required to build the project from source using as much externally released versioned tooling as possible. This is the minimal property lacking today.
- Corollary: This means including a vendored copy of OpenSSL or libz is not acceptable: link to them as external projects.
- Open question: How about non-released external tooling such as gnulib or autoconf archive macros? This is a bit more delicate: most distributions either just package one current version of gnulib or autoconf archive, not previous versions. While this could change, and distributions could package the gnulib git repository (up to some current version) and the autoconf archive git repository and packages were set up to extract the version they need (gnulib s ./bootstrap already supports this via the gnulib-refdir parameter), this is not normally in place.
- Suggested Corollary: The tarball should contain content from git submodule s such as gnulib and the necessary Autoconf archive M4 macros required by the project.
- Similar to how the GNU project specify the ./configure interface we need a documented interface for how to bootstrap the project. I suggest to use the already well established idiom of running
./bootstrapto set up the package to later be able to be built via./configure. Of course, some projects are not using the autotool./configureinterface and will not follow this aspect either, but like most build systems that compete with autotools have instructions on how to build the project, they should document similar interfaces for bootstrapping the source tarball to allow building.
make dist that generate today s foo-1.2.3.tar.gz files.
I think one common argument against this approach will be: Why bother with all that, and just use git-archive outputs? Or avoid the entire tarball approach and move directly towards version controlled check outs and referring to upstream releases as git URL and commit tag or id. One problem with this is that SHA-1 is broken, so placing trust in a SHA-1 identifier is simply not secure. Another counter-argument is that this optimize for packagers benefits at the cost of upstream maintainers: most upstream maintainers do not want to store gettext *.po translations in their source code repository. A compromise between the needs of maintainers and packagers is useful, so this *-src.tar.gz tarball approach is the indirection we need to solve that. Update: In my experiment with source-only tarballs for Libntlm I actually did use git-archive output.
What do you think?
 Turns out that VPS provider Vultr's
Turns out that VPS provider Vultr's

 Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut
Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut  One of the boxes was temporarily used for the plastic piecepack I got
with the
One of the boxes was temporarily used for the plastic piecepack I got
with the  One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time This article is cross-posting from grow-your-ideas. This is just an idea.
This article is cross-posting from grow-your-ideas. This is just an idea.

 A first revision of the still only one-week old (at
A first revision of the still only one-week old (at 
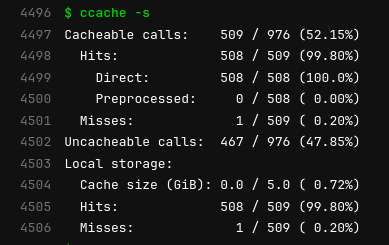 The image here comes from an example of building
The image here comes from an example of building  I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a
I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a 












 The key idea of
The key idea of 
 The talks held in the room were these below, and in each of them you can watch the recording video.
The talks held in the room were these below, and in each of them you can watch the recording video.




 As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.